An under-developing metaDTR R-package can be found on Github by the same author.
Introduction
“Dynamic treatment regimes (DTRs), also called treatment policies, adaptive interventions or adaptive treatment strategies, were created to inform the development of health-related interventions composed of sequences of individualized treatment decisions. These regimes formalize sequential individualized treatment decisions via a sequence of decision rules that map dynamically evolving patient information to a recommended treatment. An optimal DTR optimizes the expectation of a desired cumulative outcome over a population of interest. An estimated optimal DTR has the potential to:
- improve patient outcomes through adaptive personalized treatment;
- reduce treatment burden and resource demands by recommending treatment only if, when, and to whom it is needed; and
- generate new scientific hypotheses about heterogeneous treatment effects over time both across and within patients.”(Laber et al. 2014)
We consider the development of DTRs using data from Sequential, Multiple, Assignment Randomized Trials (SMART) (Lavori and Dawson 2000; Murphy 2005a; Nahum-Shani et al. 2012). See Figure 1 for a concrete example of a hypothetical SMART design for addiction management that is introduced in Chakraborty and Murphy (2014). “In this trial, each participant is randomly assigned to one of two possible initial treatments: cognitive behavioral therapy (CBT) or naltrexone (NTX). A participant is classified as a non-responder or responder to the initial treatment according to whether s/he does or does not experience more than two heavy drinking days during the next two months. A non-responder to NTX is re-randomized to one of the two subsequent treatment options: either a switch to CBT, or an augmentation of NTX with CBT (CBT+NTX). Similarly, a non-responder to CBT is re-randomized to either a switch to NTX, or an augmentation (CBT+NTX). Responders to the initial treatment receive telephone monitoring (TM) for an additional period of six months. One goal of the study might be to construct a DTR leading to a maximal mean number of non-heavy drinking days over 12 months.” (Chakraborty and Murphy 2014)
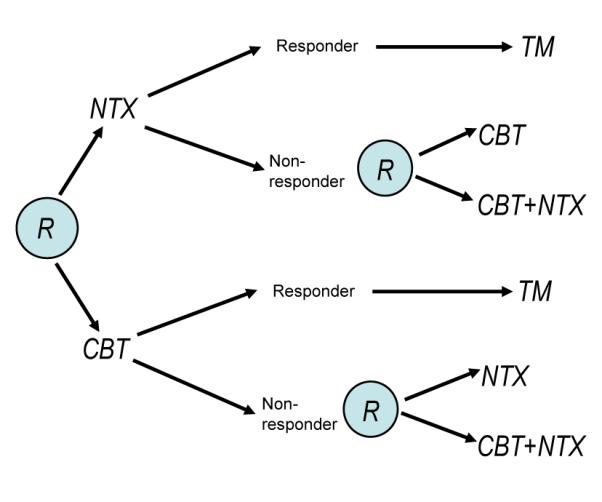
Figure 1: Hypothetical SMART design schematic for the addiction management example (an ‘R’ within a circle denotes randomization at a critical decision point)
DTRs offer a framework for operationalizing the adaptive decision making in clinical practice and thereby potentially improving it. They can be conceptualized as decision support systems for the clinicians-one of the key elements of the Chronic Care Model (Wagner et al. 2001).
Before moving to technical details of optimizing DTR, we here discuss a little bit about why not combining best treatment at each stage that are obtained from separate randomized trials. This way does not necessarily give the optimal DTR, due to:
- Delayed Therapeutic Effect
- Treatment I may not appear best initially but may have enhanced long term effectiveness when followed by a particular “maintenance” treatment (Positive Synergies)
- Treatment I may produce a higher proportion of responders but also result in side effects that reduce the variety of subsequent treatments for those that do not respond, Or the burden imposed by treatment I may be sufficiently high so that non-responders are less likely to adhere to subsequent treatments (Negative Synergies)
- Diagnostic Effect or Prescriptive Effect
- Treatment I may produce a lesser proportion of responders that treatment II, but treatment I may elicit symptoms that allow the investigator to better match subsequent treatment to the patient and thus achieve improved primary outcome to the sequence of treatments as compared to initial treatment II
- Cohort Effect or Selection Effect
- Subjects who enroll in, or who remain in or who are adherent in the trial of the initial treatments may be quite different from the subjects in SMART
In this work, we will introduce the overall structure of finding the optimal DTRs using backward induction. Moreover, we incorporate the idea of meta-learners, which are frequently used in causal inference for optimal treatment recommendation and/or heterogeneous treatment effect estimation, to facilitate the estimation of DTRs. We also evaluate the performance of the proposed meta-learner methods with the existing state-of-art methods using the same simulation setting.
Method
Notation and Problem Setup
Consider a multistage decision problem where decisions are made at
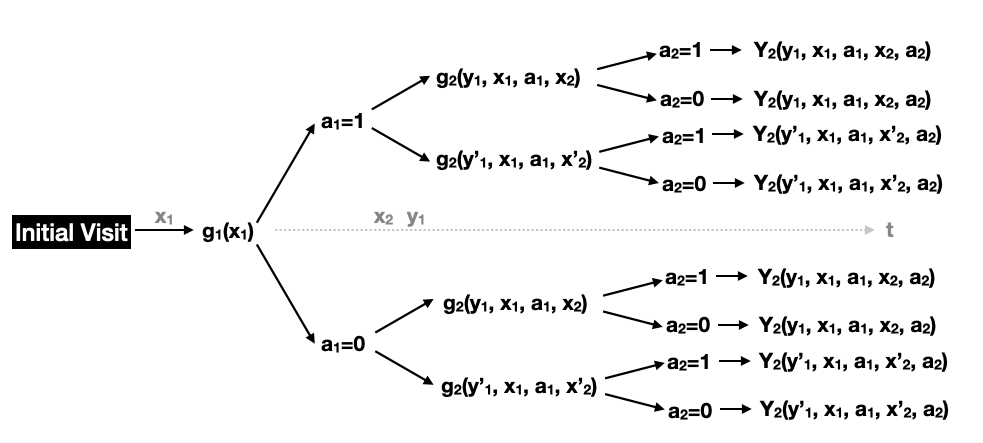
Figure 2: A two-stage study design
Following
The goal of DTR is to maximize the total rewards/outcomes:
A dynamic treatment regime (DTR) is an ordered set of deterministic decision rules, denoted as
To find solution for
Q-learning
The optimal regime may be determined via dynamic programming, also referred to as backward induction (Bellman 1966; Murphy et al. 2001; Murphy 2003). Define Q-functions, with “Q” for “quality”, as
S-learner
For simplicity, define value function
T-learner
The only difference between S- and T-learner is, in S-learner, there is only one Q-function at each stage, while in T-learner, we estimate two Q-functions, one for
To learn more about S- and T-learner, please refer to my another post.
Since Q-learning merely trains the outcomes rather than the treatment effect, so there might be error in determining the optimal treatment (Murphy 2005b). Also, this is the reason why it is known as indirect method. Therefore, another branch of methods are proposed under A-learning framework, which try to train directly on the treatment effect and obtain optimal treatment accordingly.
A-learning
A-learning is short for Advantage learning which is another main approach to seek optimal DTR (Blatt et al. 2004; Moodie et al. 2007; Murphy 2003; Robins 2004). We can define a contrast function in two arm scenario as
The value function for A-learning in terms of contrast function is
Notably, if we estimate
X-learner
X-learner is originally proposed for heterogeneous treatment effect estimation (Künzel et al. 2019). It fixes the data inefficiency in T-learner and also can outperform T-learner if unbalanced treatment allocation exists (Künzel et al. 2019). Here we extend X-learner for optimizing DTR, and the main procedure is summarized below:
- Estimate
- Impute missing potential “outcomes” by
- Lastly, combine both contrast functions to achieve the final model. One recommended way is
Simulation Studies
Case 1: Random assignment with two treatment options
In the first case, we follow the settings adopted in Zhao et al. (2015) and Zhang and Zhang (2018), which is 3-stage randomized study with only two treatment options. Treatment assignments at each stage bart() function in R package dbarts (Dorie et al. 2022).
Example R code: S-learner
We first generate the simulated data as described in the previous section using the following code. The training set has 400 samples and the testing set has 1000 samples. A, X, and Y follow the notation in Method section that stand for the treatment assignments, covariates, and outcomes, respectively, and with a suffix tr means training data, te means testing data.
set.seed(54321)
n.sbj = 400; n.test = 1000; sigma = 1
n.stage = 3
nX1 = 10; nX2 <- nX3 <- 5
## Treatment Assignments A at each stage:
A.tr = matrix(rbinom(n.sbj*n.stage,1,0.5), ncol = n.stage)
## Observed covariates X before each stage:
X1.tr = matrix(rnorm(n.sbj*nX1, 45, 15), ncol = nX1)
X2.tr = matrix(rnorm(n.sbj*nX2, X1.tr[,1:nX2], 10), ncol = nX2)
X3.tr = matrix(rnorm(n.sbj*nX3, X2.tr[,1:nX3], 10), ncol = nX3)
## Outcome/Reward generator:
y.fun <- function(X1, X2, X3, A) {
20 - abs(0.6*X1[,1])*abs(A[,1] - (X1[,1]>30)) -
abs(0.8*X2[,1] - 60)*abs(A[,2] - (X2[,1]>40)) -
abs(1.4*X3[,1] - 40)*abs(A[,3] - (X3[,1]>40))
}
Y.tr = y.fun(X1.tr, X2.tr, X3.tr, A.tr) + rnorm(n.sbj,0,sigma)
## test data:
X1.te = matrix(rnorm(n.test*nX1, 45, 15), ncol = nX1)
X2.te = matrix(rnorm(n.test*nX2, X1.tr[,1:nX2],10), ncol = nX2)
X3.te = matrix(rnorm(n.test*nX3, X2.tr[,1:nX3],10), ncol = nX3)The code of applying S-learner on the simulated data to find the optimal DTR is given below. As there are 3 stages, we estimate the Q-functions for each stage separately in a backward order, i.e., we first find Q.S1, Q.S2, and Q.S3 in the following code, the optimal dynamic treatments for any given subjects are determined.
##+++++++++++++++++ Q-learning: S-learner style +++++++++++++++++
### For stage 3 first:
S3.dat = cbind(X1.tr, X2.tr, X3.tr, A.tr[,-3], 1-A.tr[,3])
Q.S3 = bart(x.train = cbind(X1.tr, X2.tr, X3.tr, A.tr), y.train = Y.tr,
x.test = S3.dat, # prediction for potential outcomes
ntree = 200, verbose = FALSE, keeptrees = TRUE)
V3.est = pmax(Q.S3$yhat.test.mean, Q.S3$yhat.train.mean) # find V_3
### Stage 2 then:
S2.dat = cbind(X1.tr, X2.tr, A.tr[,-c(2:3)], 1-A.tr[,2])
Q.S2 = bart(x.train = cbind(X1.tr, X2.tr, A.tr[, -3]), y.train = V3.est,
x.test = S2.dat, # prediction for potential outcomes
ntree = 200, verbose = FALSE, keeptrees = TRUE)
V2.est = pmax(Q.S2$yhat.test.mean, Q.S2$yhat.train.mean) # find V_2
### Stage 1 last:
S1.dat = cbind(X1.tr, 1-A.tr[,1])
Q.S1 = bart(x.train = cbind(X1.tr, A.tr[, 1]), y.train = V2.est,
ntree = 200, verbose = FALSE, keeptrees = TRUE)
### Prediction on Testing data
Y1.1 = colMeans(predict(Q.S1, newdata = cbind(X1.te, 1)))
Y1.0 = colMeans(predict(Q.S1, newdata = cbind(X1.te, 0)))
A1.te = ifelse(Y1.1>Y1.0, 1, 0)
Y2.1 = colMeans(predict(Q.S2, newdata = cbind(X1.te, X2.te, A1.te, 1)))
Y2.0 = colMeans(predict(Q.S2, newdata = cbind(X1.te, X2.te, A1.te, 0)))
A2.te = ifelse(Y2.1>Y2.0, 1, 0)
Y3.1 = colMeans(predict(Q.S3, newdata = cbind(X1.te, X2.te, X3.te, A1.te, A2.te, 1)))
Y3.0 = colMeans(predict(Q.S3, newdata = cbind(X1.te, X2.te, X3.te, A1.te, A2.te, 0)))
A3.te = ifelse(Y3.1>Y3.0, 1, 0)
A.opt.S = cbind(A1.te, A2.te, A3.te)
### Results
Y.origin = y.fun(X1.tr, X2.tr, X3.tr, A.tr)
Y.eva.S = y.fun(X1.te, X2.te, X3.te, A.opt.S)
mean(Y.origin) # rewards from original assignments## [1] -22.92242mean(Y.eva.S) # rewards from optimized assignments## [1] 19.86825mean(Y.eva.S==20) # percentage that receive the best treatment seq.## [1] 0.992Focus on this simulated sample, we can see that in original study design, since subjects are randomized at each stage, the treatment effects are clearly not optimal, with mean outcome -22.92. However, after trained by S-learner, the average outcome following the optimized DTR can reach to 19.87 (the upper bound is 20), with 99.2% subjects receives the best treatment sequence for them.
Example R code: T-learner
With the same dataset, we now try T-learner. The code is shown below. Since we need to train two models for Q.S_.1 and Q.S_.0 at each stage representing two Q-functions.
##+++++++++++++++++ Q-learning: T-learner style +++++++++++++++++
### For stage 3 first:
S3.dat = cbind(X1.tr, X2.tr, X3.tr, A.tr[,-3])
Q.S3.1 = bart(x.train = cbind(X1.tr, X2.tr, X3.tr, A.tr[,-3])[A.tr[,3]==1,],
y.train = Y.tr[A.tr[,3]==1],
x.test = S3.dat,
ntree = 200, verbose = FALSE, keeptrees = TRUE)
Q.S3.0 = bart(x.train = cbind(X1.tr, X2.tr, X3.tr, A.tr[,-3])[A.tr[,3]==0,],
y.train = Y.tr[A.tr[,3]==0],
x.test = S3.dat,
ntree = 200, verbose = FALSE, keeptrees = TRUE)
V3.est = pmax(Q.S3.1$yhat.test.mean, Q.S3.0$yhat.test.mean) # find V_3
### Stage 2 then:
S2.dat = cbind(X1.tr, X2.tr, A.tr[,-c(2:3)])
Q.S2.1 = bart(x.train = cbind(X1.tr, X2.tr, A.tr[, -c(2:3)])[A.tr[,2]==1,],
y.train = V3.est[A.tr[,2]==1],
x.test = S2.dat,
ntree = 200, verbose = FALSE, keeptrees = TRUE)
Q.S2.0 = bart(x.train = cbind(X1.tr, X2.tr, A.tr[, -c(2:3)])[A.tr[,2]==0,],
y.train = V3.est[A.tr[,2]==0],
x.test = S2.dat,
ntree = 200, verbose = FALSE, keeptrees = TRUE)
V2.est = pmax(Q.S2.1$yhat.test.mean, Q.S2.0$yhat.test.mean) # find V_2
### Stage 1 last:
S1.dat = cbind(X1.tr)
Q.S1.1 = bart(x.train = cbind(X1.tr)[A.tr[,1]==1,], y.train = V2.est[A.tr[,1]==1],
x.test = S1.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
Q.S1.0 = bart(x.train = cbind(X1.tr)[A.tr[,1]==0,], y.train = V2.est[A.tr[,1]==0],
x.test = S1.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
### Prediction on Testing data
Y1.1 = colMeans(predict(Q.S1.1, newdata = X1.te))
Y1.0 = colMeans(predict(Q.S1.0, newdata = X1.te))
A1.te = ifelse(Y1.1>Y1.0, 1, 0)
Y2.1 = colMeans(predict(Q.S2.1, newdata = cbind(X1.te, X2.te, A1.te)))
Y2.0 = colMeans(predict(Q.S2.0, newdata = cbind(X1.te, X2.te, A1.te)))
A2.te = ifelse(Y2.1>Y2.0, 1, 0)
Y3.1 = colMeans(predict(Q.S3.1, newdata = cbind(X1.te, X2.te, X3.te, A1.te, A2.te)))
Y3.0 = colMeans(predict(Q.S3.0, newdata = cbind(X1.te, X2.te, X3.te, A1.te, A2.te)))
A3.te = ifelse(Y3.1>Y3.0, 1, 0)
A.opt.T = cbind(A1.te, A2.te, A3.te)
### Results
Y.eva.T = y.fun(X1.te, X2.te, X3.te, A.opt.T)
mean(Y.eva.T)## [1] 19.17569mean(Y.eva.T==20)## [1] 0.921Example R code: X-learner
Lastly, we show how to apply X-learner to find DTR. X-learner is more complicated than previous two learners. It starts with estimating two Q-functions just like T-learner. Then, impute the potential outcomes and find tau_.1 and tau_.0, respectively. The contrast functions are estimated by bart() as well. In the end, we combine two contrast functions with propensity score as weights. Since this is a randomized study, the propensity scores are estimated via observed proportion of
##+++++++++++++++++ A-learning: X-learner style +++++++++++++++++
prop = colMeans(A.tr)
### For stage 3 first:
#### first estimate the counterfactual outcomes from T-learner:
S3.dat = cbind(X1.tr, X2.tr, X3.tr, A.tr[,-3])
Q.S3.1 = bart(x.train = cbind(X1.tr, X2.tr, X3.tr, A.tr[,-3])[A.tr[,3]==1,],
y.train = Y.tr[A.tr[,3]==1],
x.test = S3.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
Q.S3.0 = bart(x.train = cbind(X1.tr, X2.tr, X3.tr, A.tr[,-3])[A.tr[,3]==0,],
y.train = Y.tr[A.tr[,3]==0],
x.test = S3.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
Y3.pred.0 = predict(Q.S3.0, newdata = S3.dat)
tau3.1 = (Y.tr - colMeans(Y3.pred.0))[A.tr[,3]==1]
Y3.pred.1 = predict(Q.S3.1, newdata = S3.dat)
tau3.0 = (colMeans(Y3.pred.1) - Y.tr)[A.tr[,3]==0]
#### then estimate the C()
C.S3.1 = bart(x.train = S3.dat[A.tr[,3]==1,], y.train = tau3.1,
x.test = S3.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
C.S3.0 = bart(x.train = S3.dat[A.tr[,3]==0,], y.train = tau3.0,
x.test = S3.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
#### the optimal outcome is determined by C()
V3.est = Y.tr + (C.S3.1$yhat.test.mean*(1-prop[3]) + C.S3.0$yhat.test.mean*prop[3])*
((C.S3.1$yhat.test.mean*(1-prop[3]) + C.S3.0$yhat.test.mean*prop[3] > 0) - A.tr[,3])
### Stage 2 then: (re-estimate all Qs now)
#### first estimate new Q functions:
S2.dat = cbind(X1.tr, X2.tr, A.tr[,-c(2:3)])
Q.S2.1 = bart(x.train = cbind(X1.tr, X2.tr, A.tr[, -c(2:3)])[A.tr[,2]==1,],
y.train = V3.est[A.tr[,2]==1],
x.test = S2.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
Q.S2.0 = bart(x.train = cbind(X1.tr, X2.tr, A.tr[, -c(2:3)])[A.tr[,2]==0,],
y.train = V3.est[A.tr[,2]==0],
x.test = S2.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
#### estimate counterfactual outcomes
Y2.pred.0 = predict(Q.S2.0, newdata = S2.dat)
tau2.1 = (V3.est - colMeans(Y2.pred.0))[A.tr[,2]==1]
Y2.pred.1 = predict(Q.S2.1, newdata = S2.dat)
tau2.0 = (colMeans(Y2.pred.1) - V3.est)[A.tr[,2]==0]
#### estimate the C() for stage 2
C.S2.1 = bart(x.train = S2.dat[A.tr[,2]==1,], y.train = tau2.1,
x.test = S2.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
C.S2.0 = bart(x.train = S2.dat[A.tr[,2]==0,], y.train = tau2.0,
x.test = S2.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
#### the optimal outcome is determined by As
V2.est = V3.est + (C.S2.1$yhat.test.mean*(1-prop[2]) + C.S2.0$yhat.test.mean*prop[2])*
((C.S2.1$yhat.test.mean*(1-prop[2]) + C.S2.0$yhat.test.mean*prop[2] > 0) - A.tr[,2])
### Stage 1 last:
#### first estimate new Q functions:
S1.dat = cbind(X1.tr)
Q.S1.1 = bart(x.train = cbind(X1.tr)[A.tr[,1]==1,],
y.train = V2.est[A.tr[,1]==1],
x.test = S1.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
Q.S1.0 = bart(x.train = cbind(X1.tr)[A.tr[,1]==0,],
y.train = V2.est[A.tr[,1]==0],
x.test = S1.dat, ntree = 200, verbose = FALSE, keeptrees = TRUE)
#### estimate counterfactual outcomes
Y1.pred.0 = predict(Q.S1.0, newdata = S1.dat)
tau1.1 = (V2.est - colMeans(Y1.pred.0))[A.tr[,1]==1]
Y1.pred.1 = predict(Q.S1.1, newdata = S1.dat)
tau1.0 = (colMeans(Y1.pred.1) - V2.est)[A.tr[,1]==0]
#### estimate the C() for stage 1
C.S1.1 = bart(x.train = S1.dat[A.tr[,1]==1,], y.train = tau1.1,
ntree = 200, verbose = FALSE, keeptrees = TRUE)
C.S1.0 = bart(x.train = S1.dat[A.tr[,1]==0,], y.train = tau1.0,
ntree = 200, verbose = FALSE, keeptrees = TRUE)
### Prediction on Testing data (based on Cs now, not Qs)
tau1.1 = colMeans(predict(C.S1.1, newdata = X1.te))
tau1.0 = colMeans(predict(C.S1.0, newdata = X1.te))
A1.te = ifelse(tau1.1*(1-prop[1]) + tau1.0*prop[1] > 0, 1, 0)
tau2.1 = colMeans(predict(C.S2.1, newdata = cbind(X1.te, X2.te, A1.te)))
tau2.0 = colMeans(predict(C.S2.0, newdata = cbind(X1.te, X2.te, A1.te)))
A2.te = ifelse(tau2.1*(1-prop[2]) + tau2.0*prop[2]> 0, 1, 0)
tau3.1 = colMeans(predict(C.S3.1, newdata = cbind(X1.te, X2.te, X3.te, A1.te, A2.te)))
tau3.0 = colMeans(predict(C.S3.0, newdata = cbind(X1.te, X2.te, X3.te, A1.te, A2.te)))
A3.te = ifelse(tau3.1*(1-prop[3]) + tau3.0*prop[3]> 0, 1, 0)
A.opt.X = cbind(A1.te, A2.te, A3.te)
### Results
Y.eva.X = y.fun(X1.te, X2.te, X3.te, A.opt.X)
mean(Y.eva.X)## [1] 19.55917mean(Y.eva.X==20)## [1] 0.959Case 1: Simulation Results
In previous subsections, we only see the results from a single simulated dataset. To have a better understanding of the methods, we apply the meta-learners on 500 simulated datasets and increase the testing sample size to 10,000, which is adopted in the literature. The mean and standard deviation of estimated
| n = 200 | n = 400 | n = 800 | |
|---|---|---|---|
| S-learner | 17.76 (0.98) | 19.36 (0.31) | 19.53 (0.2) |
| T-learner | 11.89 (2.64) | 18.55 (0.64) | 19.48 (0.18) |
| X-learner | 15.82 (1.04) | 19.3 (0.29) | 19.64 (0.13) |
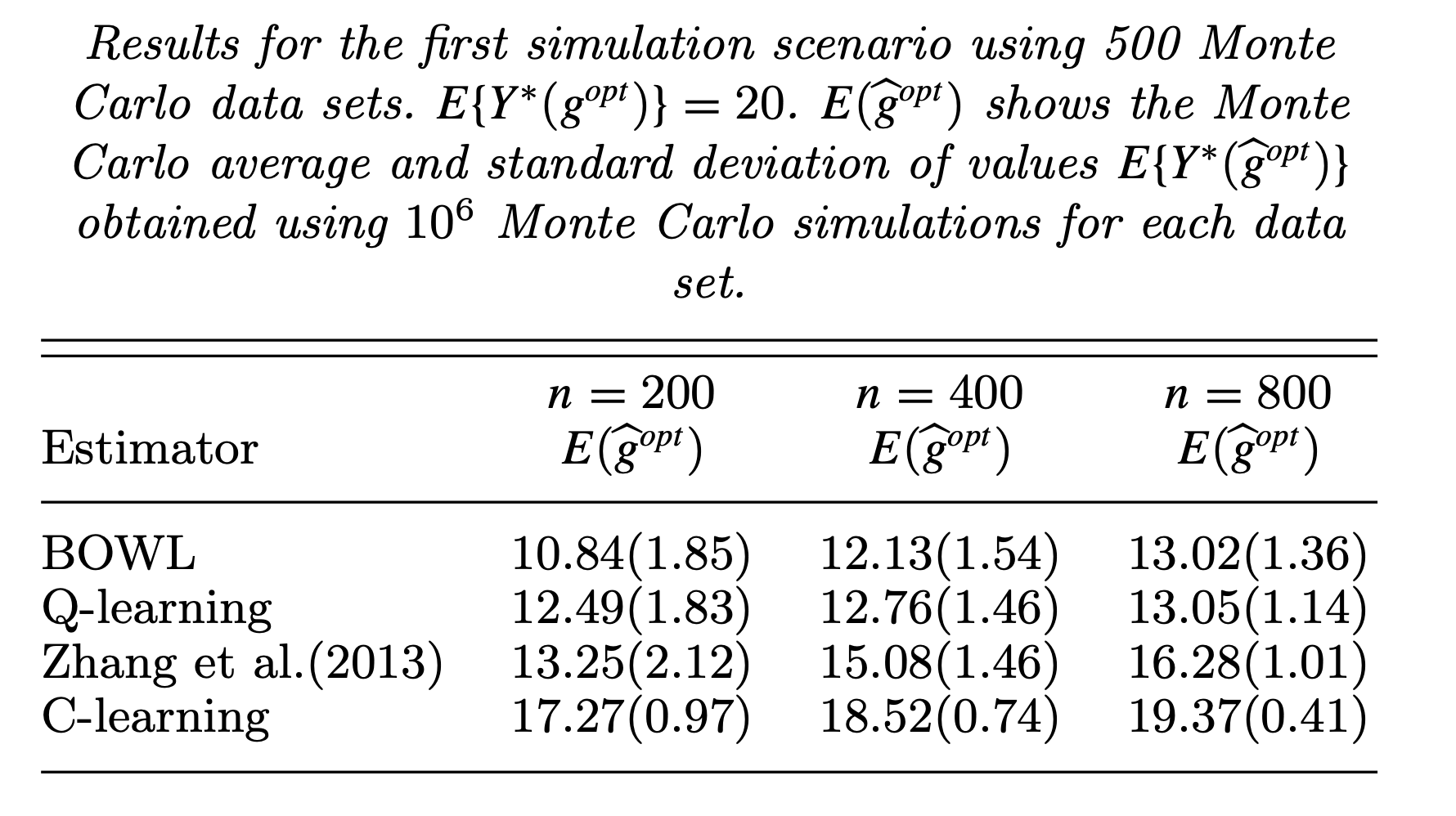
Figure 3: Simulation results from other literatures with the same simlation setting
Case 2: Two stage rewards
In Case 1, intermediate rewards are set to be 0, while in Case 2, these rewards will be taken into consideration, or in other words, the weights are now
Case 2: Simulation Results
Similar to Case 1, the sample size of training varies from 100, 200, and 400, and validation set 10,000. We repeat 500 times for each scenario. The mean and variance of the estimated DTR is provided in the Table 2. The optimal mean DTR in this setting is
| n = 100 | n = 200 | n = 400 | |
|---|---|---|---|
| S-learner | 2.933 (0.497) | 3.081 (0.17) | 3.241 (0.106) |
| T-learner | 3.039 (0.084) | 3.184 (0.077) | 3.384 (0.087) |
| X-learner | 3.006 (0.067) | 3.104 (0.078) | 3.377 (0.102) |
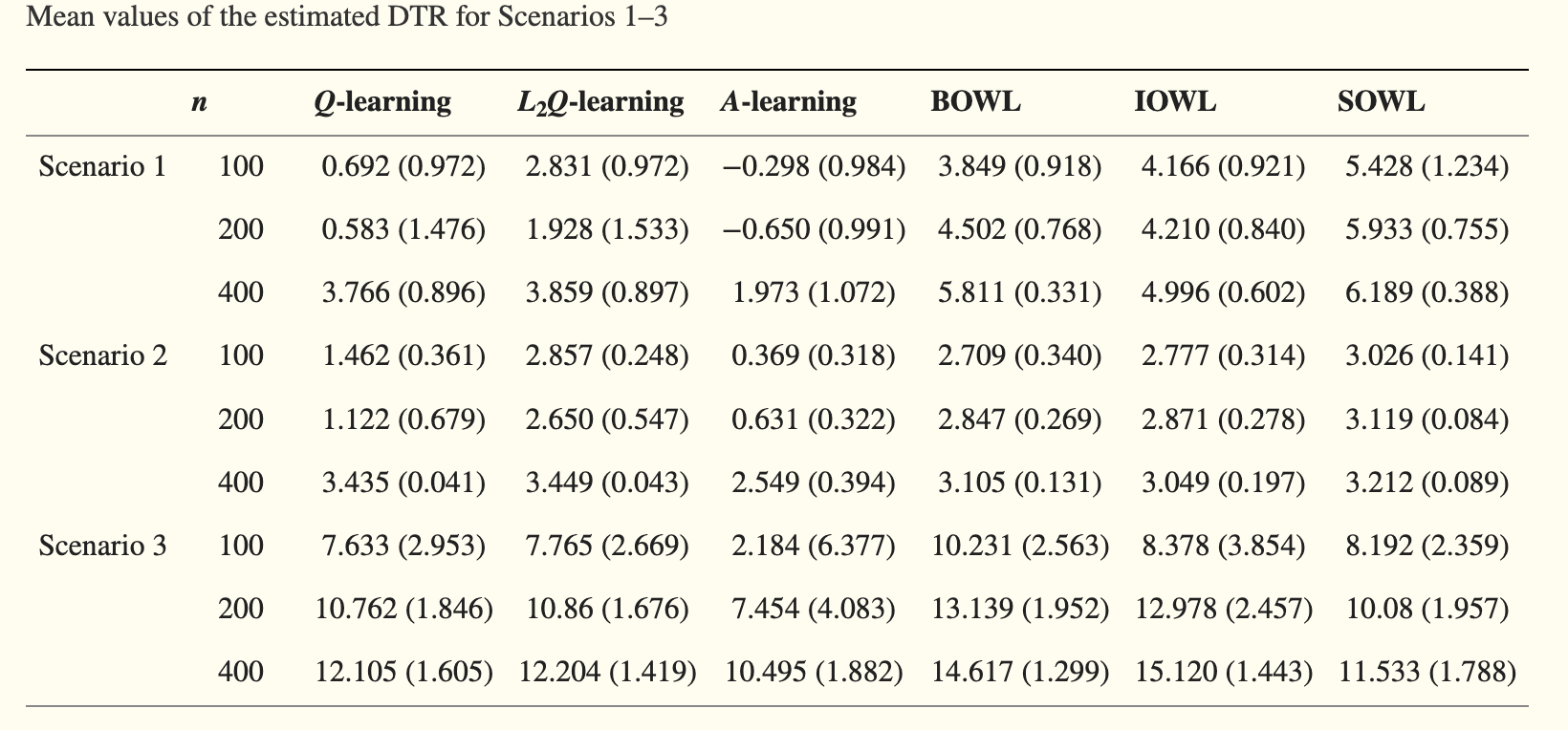
Figure 4: Simulation results for Case 1 (Scenario 3) and Case 2 (Scenario 2) from Zhao (2015)
Discussions
Multi-armed Experiment
In our previous discussions, we merely focus on scenarios with only two treatment options. When there are more than two arms, Q-learning approaches can easily be extended in most cases, it just has more Q-functions at each stage corresponding to each arm, but the value function is still well-defined and readily obtainable. However, most A-learning methods are not straightforward under multi-armed settings. The main reason is, the target quantity, the treatment effect or contrast function, need to be carefully tailored. For example, one potential way of adjustment for A-learning methods is to work on a one-versus-rest schema, or focus on pairwise comparisons between any two arms, i.e., one-versus-one schema.
These conclusions are also true for meta-learners. S- and T-learner method can easily deal with multiple-treatment scenarios but for X-learner, careful adjustments are required.
Non-randomized Design
In general, there are two sources of confounding in DTR, one comes from the unobserved influential covariates, and the other comes from past treatment assignments. For the first one, we can eliminate the impact of unobserved confounders through randomization. The second one is handled by the optimization structure introduced in Method section. When randomization is no longer achievable, we lose the control of unobserved confounding factors, and thus, to make valid inference, we need assumptions like unconfoundedness and overlapping.
Technically, propensity score will play a more important role in non-randomized studies especially for A-learning approaches, as it could provide additional security to the model misspecification, known as double robustness, along with the outcome models. Notably, for Q-learning methods, propensity score is not involved a lot. Though lose doubly robust property, Q-learning methods can achieve better approximation of outcome models, like S- and T-learner methods with powerful base learner. More importantly, in practice, when the treatment numbers are large, estimating propensity score is problematic because overlapping assumption can easily be violated. Since propensity score can have extreme values in these cases, the estimators involved propensity score might be impaired as well.
See Appendix for an example of using metaDTR package to learn the optimal DTR from a simulated observational, multi-armed, multi-stage study.
VS Reinforcement Learning
Clearly, the whole idea of seeking optimal DTR is parallel to reinforcement learning. The key is all about balancing the short-term and long-term returns to reach the optimal rewards eventually. There are some slight differences in notation/terminology though. We know the key elements of reinforcement learning includes: a set of environment and agent states,
References
Appendix
Here we consider a simulation setting that is way more complicated than the cases used in simulation section. It is an observational, multi-armed, and multi-stage study. Consider a two-stage study that at first stage, subjects only take treatment
metaDTR is provided below:
## solve by package metaDTR:
X = list(X1.tr, X2.tr)
A = list(as.factor(A1.tr), as.factor(A2.tr))
Y = list(Y1.tr, Y2.tr)
DTRs = learnDTR(X = X,
A = A,
Y = Y,
weights = rep(1, length(X)),
baseLearner = c("BART"),
metaLearners = c("S", "T"),
include.X = 1,
include.A = 2,
include.Y = 1,
verbose = FALSE
)
## test data at baseline
X1.te = matrix(rnorm(n.test*nX1, 0, sigma), ncol = nX1)
## make recommendations based on current info
A1.opt = recommendDTR(DTRs, X.new = X1.te)
## Y2/X2 is dependent on A1 (in practice, Y2/X2 should be observed)
Y1.te = Y1.fun(n.test, X1.te, as.numeric(A1.opt$A.opt.S$Stage.1)-1)
X2.te = X2.fun(n.test, X1.te, as.numeric(A1.opt$A.opt.S$Stage.1)-1)
## then keep updating it by providing newly observed info
A2.opt = recommendDTR(DTRs, currentDTRs = A1.opt,
X.new = X2.te, , Y.new = Y1.te)
## original rewards:
mean(Y1.tr+Y2.tr)## [1] 1.66878## optimized rewards (S-learner)
mean(Y.fun(X1.te, X2.te, Y1.te,
as.numeric(A2.opt$A.opt.S$Stage.1)-1,
as.numeric(A2.opt$A.opt.S$Stage.2)-1))## [1] 6.335082## optimized rewards (T-learner)
mean(Y.fun(X1.te, X2.te, Y1.te,
as.numeric(A2.opt$A.opt.T$Stage.1)-1,
as.numeric(A2.opt$A.opt.T$Stage.2)-1))## [1] 6.106891## distribution of optimized A1:
table(A2.opt$A.opt.T$Stage.1)##
## 0 1
## 186 814## distribution of optimized A2:
table(A2.opt$A.opt.T$Stage.2)##
## 0 1 2 3
## 33 39 555 373Clearly, optimal DTR on average yields way better rewards than original assignment that without any personalization. Also, by simulation setting we know that larger A better treatment effect, which is also well reflected in the distribution of recommended treatment assignments at both stage.
Here is another example of applying package metaDTR on simulation Case 1 data. In that case, intermediate covariates can be predetermined before the study. So the optimal DTRs can be obtained immediately from the function recommendDTR(). The results are close to what we have seen in Simulation section.
X = list(X1.tr, X2.tr, X3.tr)
A = list(as.factor(A.tr[,1]), as.factor(A.tr[,2]), as.factor(A.tr[,3]))
Y = list(0, 0, Y.tr)
## training
DTRs = learnDTR(X = X,
A = A,
Y = Y,
weights = rep(1, length(X)),
baseLearner = c("BART"),
metaLearners = c("S", "T"),
include.X = 1,
include.A = 2,
include.Y = 0,
verbose = FALSE
)
## estimate optimal DTR for testing data:
optDTR <- recommendDTR(DTRs, currentDTRs = NULL,
X.new = list(X1.te, X2.te, X3.te))
## S-learner results:
Y.eva.S = y.fun(X1.te, X2.te, X3.te,
matrix(as.numeric(unlist(optDTR$A.opt.S))-1, ncol = 3, byrow = F))
mean(Y.eva.S)## [1] 19.61549## T-learner results:
Y.eva.T = y.fun(X1.te, X2.te, X3.te,
matrix(as.numeric(unlist(optDTR$A.opt.T))-1, ncol = 3, byrow = F))
mean(Y.eva.T)## [1] 19.44285