Introduction
Positive and unlabeled learning, or positive-unlabeled (PU) learning, refers to the binary classification problem where only positive labels are observed and the rest are unlabeled. Since unlabeled part of data consists of both positive and negative instances, naively treating them as negative and performing a standard classification learning algorithm will underestimate the probability of being positive (Ward et al. 2009; Peng Yang et al. 2012). Without providing negative instances in the training set, however, will prevent the direct use of well-developed supervised classification methods. To break through this dilemma, dozens of PU learning algorithms have been proposed in the past two decades.
One way to bypass the lack of negative instances is to disregard the unlabeled part and only learn from positive instances. Given this underlying idea is similar to one-class classification problem, which is designed do classification when the negative instances are absent, poorly sampled, or not well defined (Khan and Madden 2014), many existing one-class learning algorithms could be easily formulated to PU learning (Pengyi Yang, Liu, and Yang 2017), such as Positive Naive Bayesian (PNB) (Wang et al. 2006; Calvo, Larrañaga, and Lozano 2007), one-class SVM (Joachims 1999; De Bie et al. 2007; W. Li, Guo, and Elkan 2010), and one-class KNN (Munroe and Madden 2005). However, since unlabeled instances are not used during the training step, it may not be competitive to those algorithms which could effectively utilize information from both positive and unlabeled instances.
To better utilize the unlabeled instances, one class of algorithms adopt a heuristic two-step strategy (Manevitz and Yousef 2001; Yu, Han, and Chang 2002; Liu et al. 2002, 2003; X. Li and Liu 2003; Peng Yang et al. 2012). In the first step, instances that are likely to have negative labels are identified by certain similarity, or distance metrics. In the second step, a classifier is developed based on the positive instances, quasi-negative instances detected in the first step, and remaining unlabeled instances. Alternatively, another branch of methods let positive and unlabeled instances share different weights in the loss function and/or classification model to account for the asymmetric nature of PU learning problem. Many existing classification algorithms that are able to incorporate weights have been studied, such as naive Bayes (Nigam et al. 2000), biased SVM (Liu et al. 2003), and biased logistic model (Lee and Liu 2003). One potential drawback of the aforementioned methods is they either explicitly or implicitly rely on the assumption that data are generated from a mixture model (Nigam et al. 2000). Hence, they are more appropriate for deterministic scheme but not probabilistic scheme, following the nomenclature proposed by Song et al. (Song and Raskutti 2019).
Meanwhile, a more theoretical viewpoint of PU learning has been developed by putting it into a case-control framework (Ward et al. 2009), given the fact that the way of sampling is not the same for positive set and unlabeled set. In positive set, only instances with positive true label are sampled, which are called cases. Unlabeled set, on the other hand, is a complete random sampling from the population, which serves as controls. Under this framework, Ward et al. are able to estimate the underlying positive-negative logistic model from observed positive-unlabeled data by expectation-maximization (EM) algorithm (Dempster, Laird, and Rubin 1977). Recently, Song et al. (Song and Raskutti 2019) extend this method with penalty terms to accomplish variable selection, and convergence is guaranteed. Denote
Recently, researchers incorporate bagging (Breiman 1996) idea into the PU learning to generate final classifier by assembling multiple PU classifiers estimated from bootstrap sampling (Mordelet and Vert 2011; Mordelet and Vert 2014; Claesen et al. 2015; Pengyi Yang et al. 2016). This approach takes advantage of bagging feature to reduce noise from modeling directly with unlabeled instances and obtain more stable predictions. Rather than using unanimous probability to sample, AdaSample (Pengyi Yang et al. 2018), a more boosting-like algorithm, applies different sampling probability at each step, and the probability is calculated from PU model estimated in the previous iteration. The performance of the adopted PU classifier for the bootstrap sample is of great importance to the success of this set of methods.
PUwrapper (basic idea)
The PUwrapper provides a general framework that could apply to any traditional supervised learning algorithm but still make them work for the Positive-Unlabeled dataset.
In positive-only data scene, there are two fundamental setup:
- Condition 1. Positive instances are completely random selection from positive population;
- Condition 2. The unlabeled instances are a random sampling from the population.
As the observed dataset is not a random sample from the population but a random sample for either the positive or the unlabeled, it satisfies the case-control framework. But among the unlabeled, there is a mixture of true positive and negative instances which makes it hard to directly adopt traditional methods upon this case-control problem.
Since only part of
Observed likelihood:
Full likelihood:
EM algorithm (adjusted): maximize the observed likelihood by iteratively maximize the full likelihood conditioning on the observed data and estimated parameters. Here let
E-step:
M-step: In M-step, we maximize the expectation of full log-likelihood described in E-step
Mapping: We add an additional step here to make it work like a wrapper that are free of the specification of functional structure of
How to achieve c?
In formula
- How to do variable selection during EM
If we want to accomplish variable selection during the EM algorithm, the objective function at M-step is adjusted to the following
Basically, as a wrapper, we do not need to know specific value of
Unbalanced scenarios (observation unbalancedness and population unbalancedness) This is not something we are interested for a wrapper. If necessary, we could start with rewriting c as
How to find out the optimal cutoff without knowing the true
We are able to generate a sequence of estimated probability for each unlabeled instance, even though the probability itself is biased, the order is maintained (shown by ROC curve). For application purpose, sometimes we need to provide a clear category for instances which could be a problem when true
Illustration via Simple Simulation Studies
In the first simulation study, we compare the outcomes from knowing true
Based on the results, there are several comments:
- Biased
- Using estimated
- Initial value to start EM algorithm does not matter a lot
- True
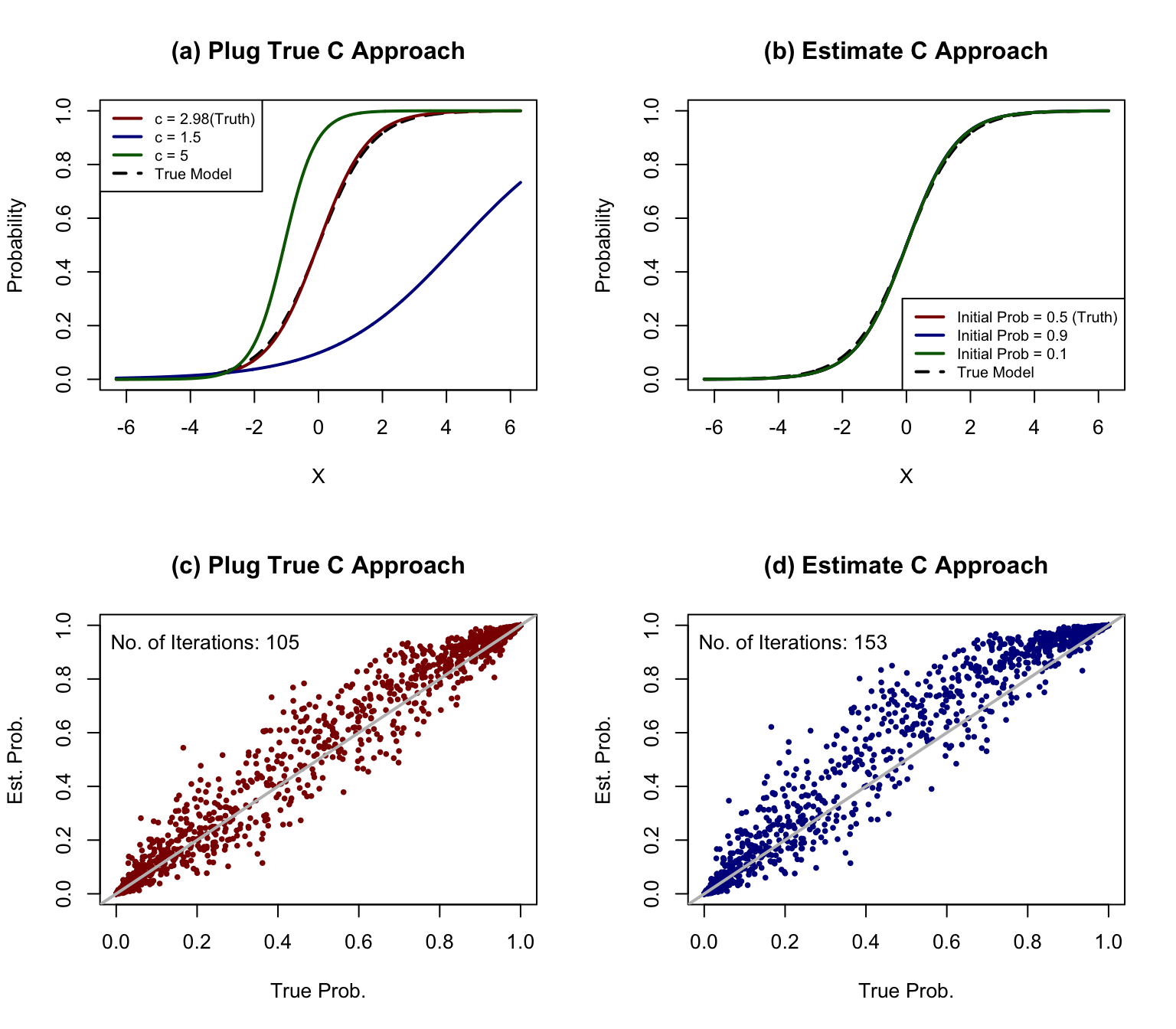
Figure 1: Simple examples of Wald’s method and the proposed improved method with estimated c. Panel (a) and (b): univariate model
In second simulation study, we wrap two basic supervised learning algorithms: random forests (RF) and penalized logistic regression (PLR). At the meantime, we would like to conduct variable selection during the process. For PLR, we adopt LASSO at each EM iteration, while for RF, we use variable importance score as the weights. We generate 100 variables where only 5 of them are related to the outcome. In other words, the rest of them are purely noise. In Figure 2, we display the results based on PUwrapper, and the selected variables, or variable importances are given in panel (c) and (f).
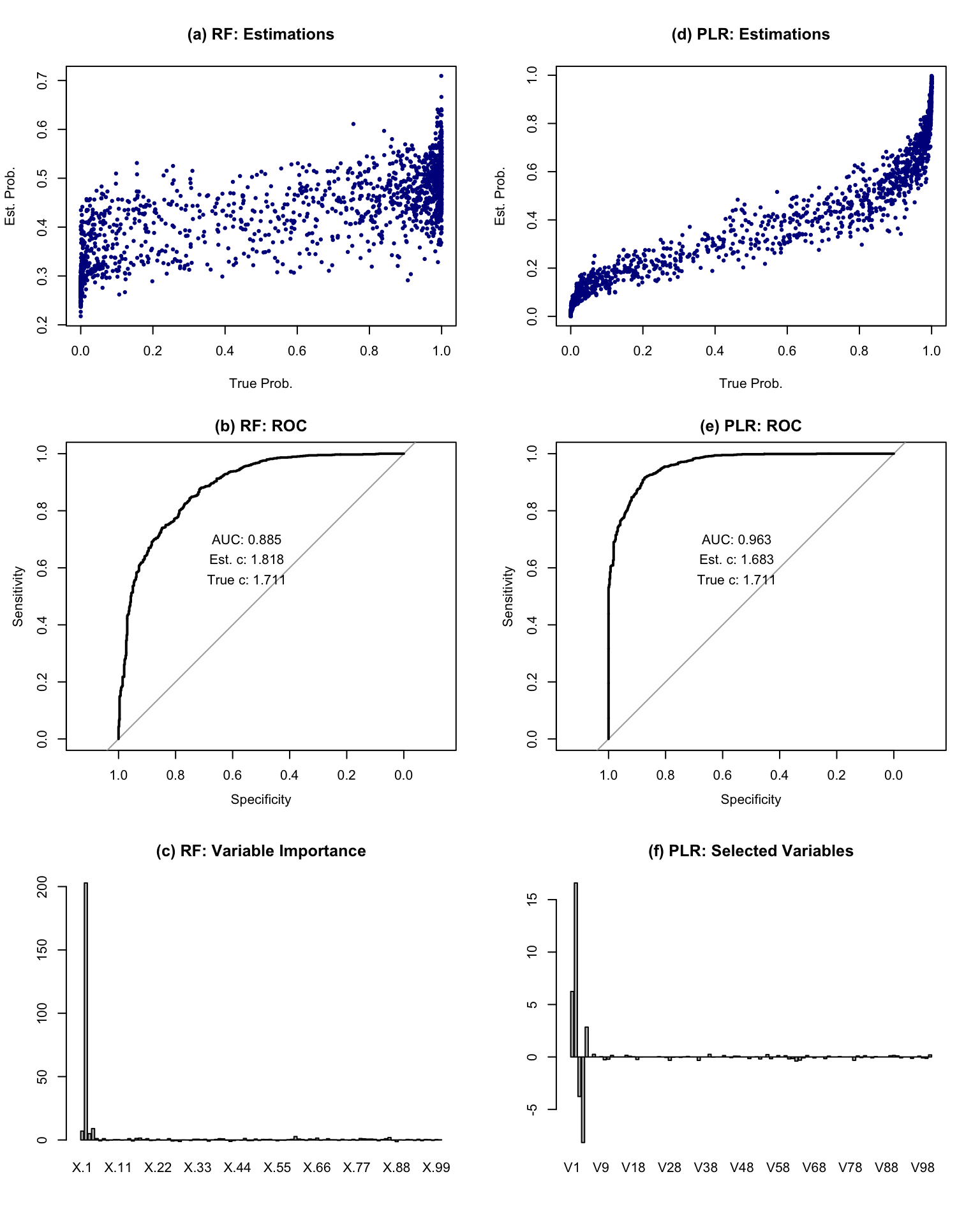
Figure 2: Simple examples of PUwrapper. Panel (a) and (b): Random Forests; Panel (c) and (d): Penalized Logistic Regression. The baseline model is